
Text Recognizing Technology is becoming an increasingly vital element today. But how exactly does it work?
Text recognition has been around for ages. Nowadays, experts estimate this technology’s market value to be around $10 billion. But how exactly does it work? Well, for a simple answer, it’s a blend of AI and OCR tech.
But we’ll have to dig in deeper for a longer answer. In this article, we’ll talk about Text Recognizing Technology, how it works with OCR types, and how it can help extract text from images. So, let’s begin.
What Is Text Recognizing Technology?
Text recognition technology is the process of converting a scanned image of text into text. It’s usually called optical character recognition, often shortened to just OCR; these tools depend on various technologies. While OCR has been around for around 90 years, it has become a key technology in today’s content.
Text recognition is helpful because it can be used to convert a scanned image of text into text. It is also widely used for scanning documents and anything with words. Hence, the technology employs AI nowadays to extract accurate texts from images/documents.
Optical character recognition (OCR) depends on recognizing each character present in an image, hence the term of turning an image of text into text. While online OCR tools are primarily used for scanning images, they also scan books, magazines, and other printed materials.
OCR software programs are designed to recognize characters in images by looking for patterns that resemble letters. Or numbers in a particular font and then assigning those patterns to corresponding keyboard characters.
How Text Recognition Works Through 4 Main OCR Types
OCR technology has evolved into many branches. While the primary pillar is always the classic OCR (optical character recognition), nowadays, it’s a blend of classic and modern AI tech. So, to help you understand how modern OCR works, here are four types of OCR:
1. OCR
OCR is the classic optical character recognition that we know, which analyzes and recognizes each character present in an image or a document. One of these tools is Tesseract OCR in Python.
2. OMR
OMR is more or less the same as OCR, but except for characters, it recognizes markings. Therefore, it helps scan any paper containing mathematical equations, names, signs, etc.
3. ICR
ICR or intelligent character recognition is OCR but enthused with AI. Therefore, it enables the OCR tool to recognize characters that might be undiscernible by classic OCR.
4. IWR
IWR, or intelligent word recognition, analyzes a document or paper to scan and extract words out of it. This aspect of OCR uses AI as well.
How Text Recognition Helps Extract Text From Images In Four Steps
Understanding how the OCR tech works require us to use an image extractor work. In this section, we’ll look at how each step you take when using such a text-recognizing tool and how it helps extract text from images. So, let’s begin:
1. OCR Scans The Image
The first thing you do in any Text Recognizing tool uploads the image. Or some image-to-text extractors can also upload the URL. Either way, your image should look like this when you upload the image:

Now, once you upload the image, the OCR begins its job. That’s when it scans your image thoroughly. It won’t look like anything to the naked eye, as it barely takes a fraction of a second. However, it thoroughly analyzes the image.
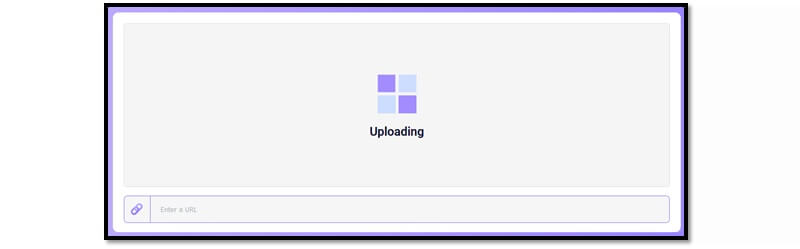
The first thing OCR does is recognize how much of the text is type-written and how much of it is hand-written. It’s one or the other, and rarely both since it’s possible only in documents or other images of such nature.
2. It Recognizes Text With Various OCR Types
The next step sees the tool analyzing your image. This section also happens behind the screen, as the tool thoroughly recognizes the text present in the image. It depends on which of the four OCR types is needed the most.
If the words aren’t easy to read, blurred, broken, or hand-written crudely, then OCR’s AI branches, such as IWR & ICR, work the most. Since intelligent character recognition is more suitable for reading images with crude text, it allows the tool to extract text from image.
That’s why modern image extractors employ various OCR branches, so they can extract text from all sorts of images—even blurry or crude text.
3. Generates Text From The Image & Compares It
The next step in the process is extracting the text that it has detected. This requires the tool to write down the words, characters, punctuations, and even signs. All this happens before the tool presents the text to the user in text form.
However, this process aims to ensure that the text and image are similar. Once again, this entire process takes barely 10-15 seconds. But, in the background, the image extractor works hard to present the outcome to the user.
4. You Get Editable Text
The last stage of the process is when the tool gives you editable text. This Window allows you to copy the text or save it directly to your computer in a document. So, the image we were trying to extract was this:

And when we extract text from the image, it looks like this:
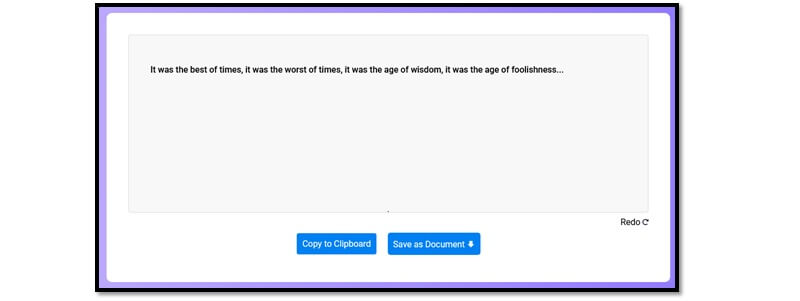
As you can see, the tool has extracted text efficiently. So, the entire process took less than 10 seconds. But, behind all that, what we discussed was happening. So, what happens from here on? You can either copy the text to the clipboard:
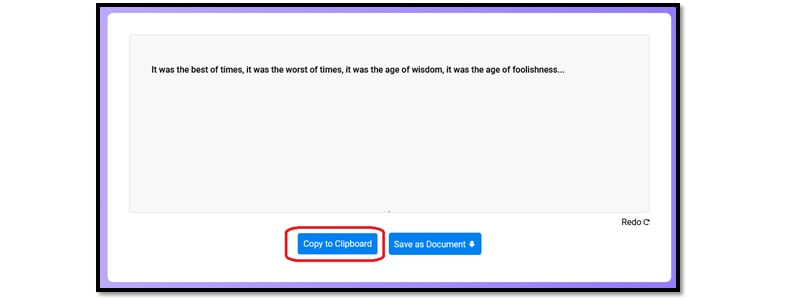
And later, you can paste it to a document or anywhere you like. Or, you can save this information in the DOCX format using this option:
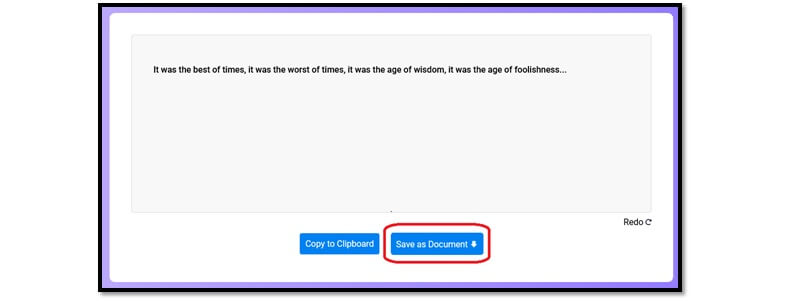
This will save your file in a word document. However, only capable text-recognizing tools allow you to do this. Most tools would simply allow you to copy and paste your text.
Conclusion
This is how you get editable text from an image using Text Recognizing Technology. Now, it all comes down to the tool you’re using, but in most cases, this is how it’s going to look and work.
Also, you can check: How to Create a Consistent Brand Image in 7 Steps.





